


Data Architecture Review - Are we right?
Orientation when the possibilities are unlimited

Data Architecture is a hard job. How do you know which systems, components and capabilites are the right ones for your current and future data & analytics needs? What if we decide wrong and don’t get what we imagined, the costs are to high or it is to complex to handle?
How it started…
When I get a request to review a data architecture I come typically with an outside-in perspective. This means I can only build on what I know from the customer, about the technology and what works for other customers from my experience. So first I have to understand the customers needs, general aspects, the way how they come to this data architecture and sometimes als technology- and data-specific aspects for a common understanding. It is always good if you understand the use cases they want to implement in the future - but surprisingly this is not always given.
Furthermore there are typically aspect which are fixed and can not be changed, whatever I will tell them.
The customer data architecture to be evaluated:
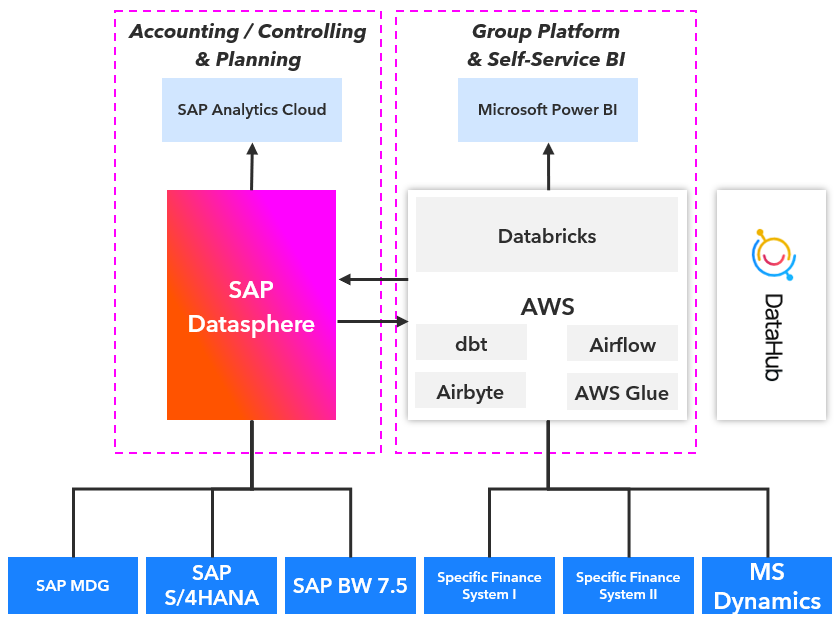
How it is going…
Asking the right question is the key. A direct talk is the best to not just get the answer but also understand what is important to them. Where is the pain? What do they want to hear? Where are the limits? Based on this I can describe or recommend about the data architecture and point to consider, changes I would recommend and so on. Some typical data architecture questions to start with from my side are (except):
Which architectural aspects are already fixed and will not change as a result of our recommendations?
To what extent has thought been given to the topic of Enterprise Data Catalog? Databricks Unity and Datasphere Catalog cannot fulfill this task at the moment.
Separate data management concepts (SAP/Databricks) and organization - What about overarching information/analysis requirements?
Users prefer certain frontend - How do you deal with this when overarching requests come in? (e.g. Power BI user wants to access SAP Datasphere data)
Should access from SAP Datasphere to Databricks take place via data federation at runtime or should data be kept redundant on request?
How should requirements in the area of machine learning be handled if overarching data (SAP/non-SAP) is required for this?
How far does the self-service concept go? What are the business departments themselves doing in terms of data management on the platforms, and also with Power BI and SAC?
Outlook
If there is already a specific variant of the data architecture, it is possible people just want a confirmation that they did their job right. Also typically there is no bad architecture in such situations, it is rather an optimization problem. If you do not have super specific challenges, todays typical components should do the job and the interplay between the components can be subject to change. Don’t forget, the typical customer is not Google, Spotify, Uber or AWS. But such a process to include an outside-in perspective can help to cut out some future problems. This will save time and money for the customer.